Programming has been a passion of mine since I was very young. I taught myself to write programs from the manual that came with my home computer and have never stopped since then. Most of what I do today is either written as shell scripts or C code. Here’s a brief overview of the software I have to offer.
Table of Contents
jdupes – find and manipulate duplicate files
winregfs – mount Windows registry hives as a FUSE filesystem
Tritech Service System – embedded Linux for computer repair
zeromerge – merge complete parts of two incomplete files
imagepile – combine flat disk images, merging duplicate blocks
jodyhash – fast hashing algorithm (64, 32, or 16 bits wide)
lzjody – compression algorithm with a notable transformation step
snd2remote – play sounds on a remote machine
alterego – run chroot binaries within a native system
jdupes
A file duplicate scanning tool for Linux, Windows, Mac OS X, and most UNIX-like platforms that offers a wide variety of actions to take on duplicate file sets and filters to control how those duplicate sets are found and arranged. Forked from fdupes and receiving a lengthy blog post about its growth during development, jdupes is one of the quickest and most versatile duplicate file finders in existence.

winregfs
This one always turns heads and cranks necks when I explain what it does: it’s a FUSE filesystem that allows the use of Windows registry files as if they are an ordinary filesystem full of text and binary files. With winregfs, scripts that need to work on Windows registry hive files become effortless. Other tools exist to work with Windows registries under Linux such as reged (part of chntpw which winregfs is actually based on) but none of them are easy to incorporate into a shell script. I use winregfs to extract the Windows version and edition, set driver services from System startup to Boot startup (echo 0 > HKLM\ControlSet001\services\[service]\Start.dw), copy user settings from one hive to another, and much more. It is still buggy and certain types of data will cause it to crash, but for the vast majority of registry data I have to work with it is generally stable and does what it was designed to do very well.
Tritech Service System (TSS)
It’s easier to delete malicious software infections on Windows machines from a live Linux CD than from within the infected Windows installation. That’s why I originally created the Tritech Service System: my live CD distribution of choice went without updates for several years and became useless, so I had to find another one or make my own. The history of TSS is complex but the end result is an extremely compact yet modern live Linux CD, USB, or network boot system that runs entirely in RAM and doesn’t require access to the original boot device to be useful. TSS consists of two parts: a publicly available release which boots to a text-mode prompt and can be used to mount and work with offline Windows systems, and a set of proprietary packages which I keep to myself that take TSS from a general-purpose live Linux to an advanced diagnostic and repair tool that integrates with my work order management system at my computer service business: Tritech Computer Solutions. If you are fluent with working on a Linux command line and you don’t mind not having manual pages, you’ll probably be comfortable playing with TSS.
zeromerge
A program which takes two files that are supposed to be identical but that are incomplete and contain zeroes in “missing” blocks and merges them together into a third unified file. This tool is a little bit niche, but there was nothing else like it, so I wrote it.
A common scenario where this problem is encountered is when attempting to fetch a bunch of old torrents with the same files in a desperate attempt to download something that is no longer widely available. It’s common for people to re-share files from other torrents verbatim in different torrents that have a different info hash, and it’s easy to find magnet links for a lot of these identical or mostly-identical torrents with DHT search engines like BTDigg or BT4G. Unfortunately, it is also very common for the few lingering leeches on such old torrents to only have partial downloads of the data, with no chance of a seeder ever returning. This is a rarely discussed data loss scenario; it’s commonly said that anything put on the internet stays there forever, but this is not remotely true. Without a full seed available, many torrents don’t die, but instead become permanently incomplete. This is horribly exacerbated by torrent clients that delete files the user doesn’t want to keep such as graphics, web shortcuts, information text files, and so on, rendering one or more pieces of the important files permanently unavailable. qBitTorrent allows the user to tuck these files away in a hidden folder called .unwanted, thereby preserving the torrent’s integrity while seeding and hiding the undesired files from view, but many other clients do not do this.
This is where zeromerge comes into the picture. If you have two torrents, each with identically sized video files called “ABC-123.mp4” inside that are likely supposed to identical, you can merge them together into a unified file like so:
zeromerge first/ABC-123.mp4 second/ABC-123.mp4 ABC-123_merged.mp4
You can then replace the original files with the unified file (remember to tell your torrent client to “force recheck” the torrent data afterwards):
cp -f ABC-123_merged.mp4 first/ABC-123.mp4
mv -f ABC-123_merged.mp4 second/ABC-123.mp4
If you wish to unify both files on disk so that you can update each with progess from the other using your torrent client’s “force recheck torrent” option, you can replace the commands above with one that does a hard link:
mv -f ABC-123_merged.mp4 first/ABC-123.mp4
ln -f first/ABC-123.mp4 second/ABC-123.mp4
For Windows, you’ll need to replace the commands with the appropriate Windows command prompt versions, such as
copy /y
move /y
mklink /h
You’ll also need to use backslashes instead of forward slashes.
I have personally used this to resurrect several old seedless torrents, merging the missing data between them and becoming a seed as a result.
There is a way to do this without zeromerge if you really want to go to the trouble of doing so: create hard links between your torrent data files in advance.
imagepile
I wrote imagepile to do something that sounds simple: take a pile of flat disk image snapshots (literally block-for-block copies of a working system) and deduplicate them on the block level. My logic is that if I keep flat disk image files for (as an example) Windows 7 Home, Pro, and Ultimate, with 32-bit and 64-bit versions of each, I end up with six multi-gigabyte files that contain a huge amount of identical data. I work with such files by dumping them with “cat” or “pv” straight to disk, so if I had a way to store these huge yet heavily redundant files in a single larger file and be able to “cat” the original files out on demand, I could eliminate those redundancies and not have to rework my existing imaging workflow. I ended up realizing that I really needed to improve the way it stores the images, particularly since a “pile” consists of two big files and a bunch of smaller files that represent the original files that were added to the pile, and that’s just clumsy to keep around, plus I couldn’t quickly pull an individual image out to external media for use off-site. I thought about making a file format and writing it as a library with both a FUSE filesystem and a utility that didn’t require FUSE to load/store data, but the greatest enemy of a better solution is an existing solution that works, so I stopped developing it. It wouldn’t have been worth the significant effort required to write a 2.0 the way I envisioned.
jodyhash
Though faster algorithms with better distribution properties exist, jodyhash is my personal attempt to write a decent fast hash function. I’ve used it in winregfs, imagepile, and jdupes, and in almost all of the tests I ran on loads of trial data sets, I was able to tweak the algorithm to the point that the only collision I could trigger was two uppercase dictionary words in a massive “every English word ever” dictionary. Because it was plenty fast and my testing showed an extremely low collision rate, I happily used it for years. I switched away from it because other hashes with better properties while also running at higher speeds were available. I originally wrote it both to scratch an itch and as a learning tool, and while my collision tests showed it had great behavior for the intended data sets, other people have put it through synthetic tests that find poor avalanche and distribution properties as well as lower performance than hashes with better distribution properties such as xxHash64. Part of being a good programmer is being able to handle when a better solution exists and not fall into “not invented here” syndrome. That being said, I am still using jodyhash in standalone versions of jdupes (including a BusyBox port I am currently working on) because it turned out to have one distinct advantage over those better algorithms: jodyhash is extremely small and simple to drop into any piece of code.
lzjody
I’ll tell you right now: this doesn’t currently work and I may never bother to make it work, though it was fully functional at one point in the commit history. Ever since I was rather young, I’ve found compression algorithms to be a fascinating thing. This was my attempt to write a compression algorithm, particularly intended to work with imagepile (thus the fixed 4KiB block size) and several of the more unusual compression tactics seen in the algorithm are based on patterns I saw in disk images. The compressors called seq8/seq16/seq32 could encode a sequence of incrementing values of the bit width mentioned in their names; rather than “8,9,10,11,12” seq8 would output something that translates to “seq8(8,4)” (8-bit wide sequence, start at 8, increment 4 times) and the others worked identically on larger widths. Translation tables were especially highly compressible by these compressors because they often have long runs of incrementing characters. There were the usual LZ and RLE compressors that can be found in tons of compression algorithms today, but the most unusual and innovative bit of the whole algorithm is something I decided to call the “byte plane transformation.”
To understand what a byte plane transformation (we’ll call it BPX for short) is, you have to think about the data two-dimensionally. BPX copies the entire data block to a new data block, but does so every fourth byte at a time. When it runs out of the first set of bytes, it returns to the start but begins at offset 1 instead of 0; then offset 2 and offset 3, completing the transformation. This places all bytes of each part of a 32-bit value together, then the normal compression scanners run over the transformed data. For example, if you have a block of 32-bit values where they are identical in all but the last byte, 3/4 of the data has now been re-ordered such that it can be compressed with RLE; for a 4096-byte block, that means 3072 of the bytes will be reduced to just a few bytes of compressed RLE data.
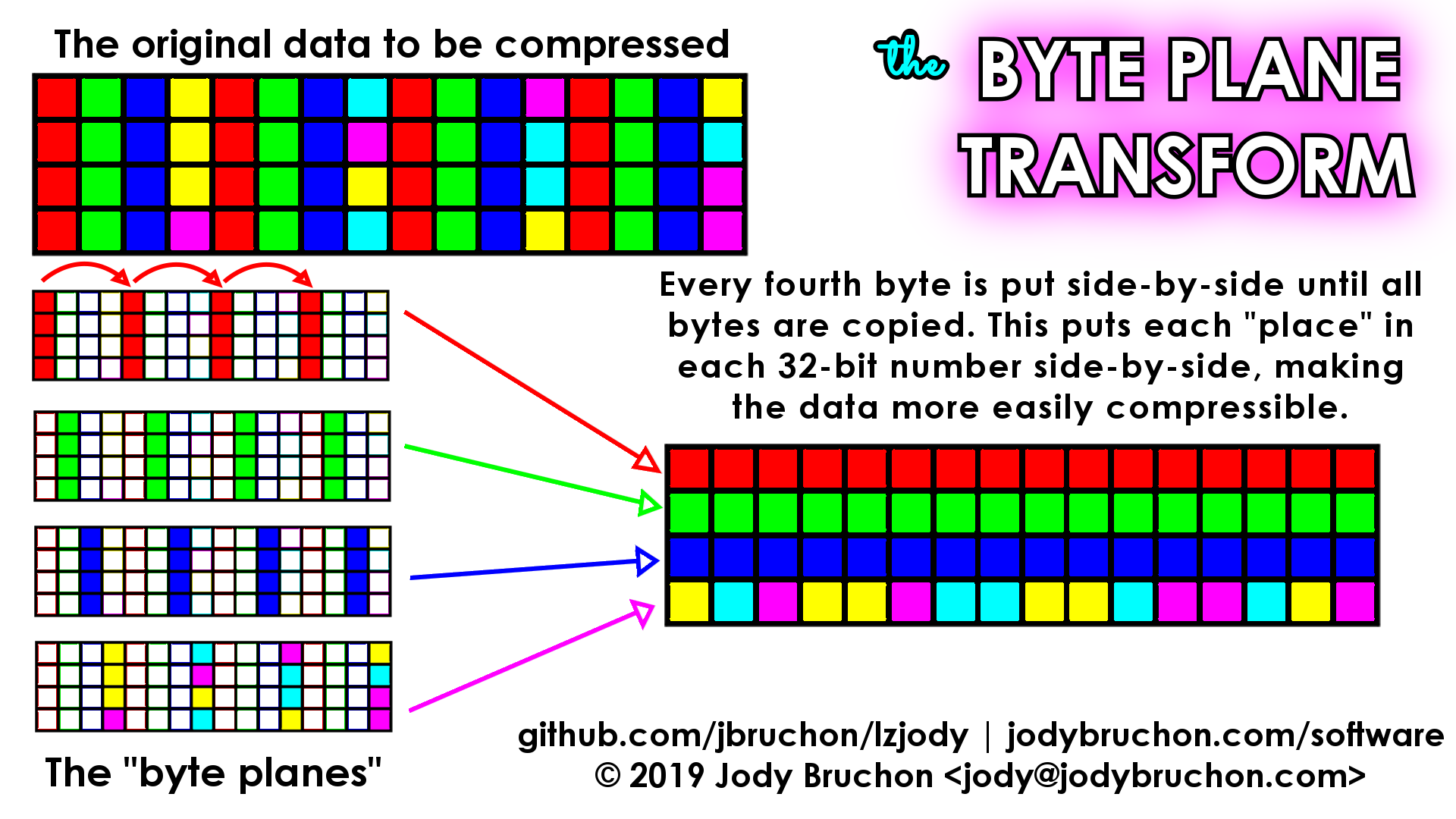
This can also help with 16-bit values in a similar situation since BPX makes the places in every other 16-bit value contiguous as well. Data with such redundancies can be seen somewhat often in on-disk data blocks. If there is an incrementing sequence in a byte other than the least significant one, BPX will render such data compressible by the seq8 compressor.
snd2remote
If you run software on a remote Linux machine across a LAN and you need to be able to play sounds and notifications on your local machine, this set of scripts and free software executables will let you do it. You can use a local command on any Linux machine attached to your LAN to trigger sound events on any listening Windows or Linux machine. The software does basic decision-making and scanning if the literal sound name is not accessible to try to improve the chances of a notification successfully playing. Broadcast and listen modes are included in the Linux/UNIX script “snd2remote” and a batch file (with required supporting executables) is also provided for Windows systems to receive events. As of the date I’m revising this entry, it’s been around a decade since I wrote this program and it’s not representative of my current work.
AlterEgo
This was my first practical C program and it’s both extremely simple and quite odd in its purpose. It hasn’t been improved much since I originally wrote it but it fills an obscure niche I couldn’t find any different solution for. The traditional way of running 64- and 32-bit programs on the same Linux system is to have separate ‘lib’ directories for each and a multilib-enabled toolchain to build the software with. I experienced huge amounts of frustration and failure trying to build a multilib toolchain by myself and I decided that I would take a different approach. I would unpack a native system of a different bitness than the current one into a directory (e.g. /chroot32) and use a series of bind mounts (/etc, /dev, /proc, /sys, /home) followed by the ‘chroot’ command to switch into the other system. Unfortunately, the issue I experienced is that I downloaded the 32-bit version of Firefox but could not run it directly because it required a chroot to the alternative system before it could be executed, so I’d have to open a terminal and type a bunch of junk manually. The simplest solution was to write a C program that would “wrap” the chroot action and the execution transparently so that if the 64-bit environment ran /usr/bin/firefox (which would be a symlink to /bin/alterego) it would automatically change the root filesystem and then run the intended binary on the user’s behalf. I have not used it in a long time (like snd2remote, this one’s quite old and not representative of my current abilities.)