Update: there is an addendum at the end of this article; I mention it because yes, in the end, I switched over to Python sets. I don’t want any Python experts cringing too hard, after all. Welcome to the joys of a C programmer adapting to Python.
For those who haven’t heard of it, youtube-dlc is a much more actively maintained fork of the venerable but stagnant youtube-dl project that was announced on the DataHoarder subreddit. I have been archiving YouTube channels for many months now, trying to make sure that the exponential boost in censorship leading up to the 2020 U.S. Presidential election doesn’t cause important discussions to be lost forever.
Unfortunately, this process has led me to have a youtube-dl archive file containing well over 70,000 entries, and an otherwise minor performance flaw in the software had become a catastrophic slowdown for me. (Side note: a youtube-dl archive file contains a list of videos that were already completely downloaded and that lets you prevent re-downloading things you’ve already snagged.) Even on a brand new Ryzen 7 3700X, scanning the archive file for each individual video would sometimes progress at only a few rejections per second, which is very bad when several of the channels I archive have video counts in the multiple thousands. The computer would often spend multiple minutes just deciding not to download all of the videos on a channel, and that got painful to watch. That’s time that could be spent checking another channel or downloading a video.
When youtube-dlc popped up and offered goodwill to the people who were treated less than favorably by the youtube-dl project maintainers, I realized that I had a chance to get this fixed. I opened an issue for it, but it became clear that the budding fork didn’t have resources to dedicate to the necessary improvement. The existing code technically worked and performance wasn’t as bad for people using much smaller archive files. Both myself and the youtube-dlc maintainer (blackjack4494) quickly identified the chunk of code that was behind the problem, so I decided to take it on myself.
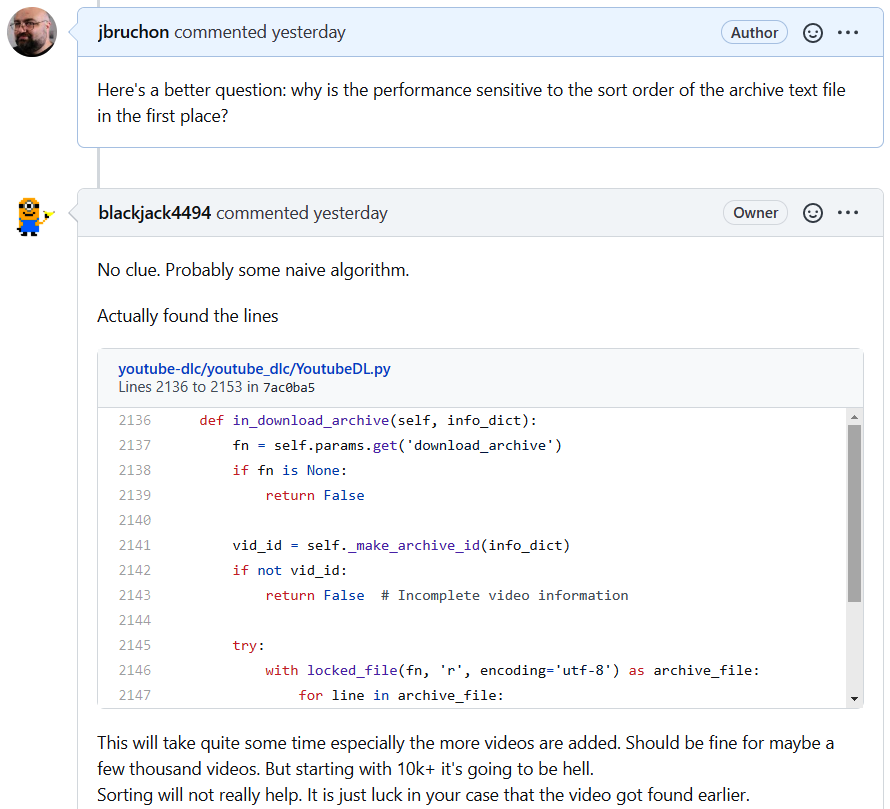
The troublesome code is cut off in the discussion screenshot, so here’s a better look at it:
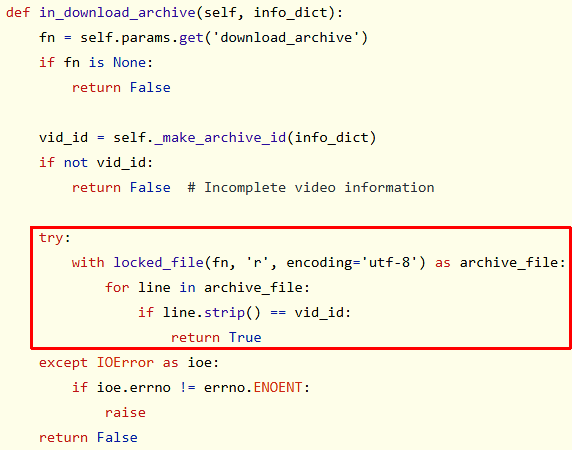
The code outlined in the red box above is opening the archive file for reading, consuming it line-by-line, and comparing the line read from the archive to the line associated with the candidate video to be downloaded. If a line exists that matches, the video is in the archive and shouldn’t be downloaded, so in_download_archive() returns True. This works fine and is a very simple solution to implementing the archive file feature, but there’s a problem: in_download_archive() is invoked for every single possible video download, so the file is opened and read repeatedly.
Some programmers may see this and ask “why is this a problem? The archive file is read for every video, so there’s a good chance it will remain in the OS disk cache, so reading the file over and over becomes an in-memory operation after the first time it’s read.” Given that my archive of over 70,000 lines is only 1.6 MiB in size, that seems to make some sense. What is being missed in all of this is the massive overhead of reading and processing a file, especially in a high-level language like Python.
An aside for programmers not so familiar with more “bare metal” programming languages: in C, you can use a lot of low-level trickery to work with raw file data more quickly. If I was implementing this archive file check code in C (some low-level steps will be omitted here), I’d repeatedly scan the buffer for a newline, reverse the scan direction until extra white space was jumped over (doing what strip() does in Python), convert the last byte of newline/white space after the text to a null byte, and do a strcmp(buffer, video_id) to check for a match. This still invokes all of the OS and call overhead of buffered file reads, but it uses a minimal amount of memory and performs extremely fast comparisons directly on the file data.
In a language that does a lot of abstraction and memory management work for us like Python, Java, or PHP, a lot more CPU-wasting activity goes on under the hood to read the file line by line. Sure, Python does it in 4 lines of code and C would take more like 15-20 lines, but unpack what Python is doing for you within those lines of code:
- Allocating several variables
- Opening the file
- Allocating a read buffer
- Reading the file into the buffer
- Scanning the buffer for newlines
- Copying each line into the “line” variable one at a time
- Trimming leading and trailing white space on the line which means
- Temporarily allocating another buffer to strip() into
- Copying the string being stripped into…
- …while checking for and skipping the white space…
- …and copy the string back out of that buffer
- Finally doing the string comparison
- All while maintaining internal reference counts for every allocated item and periodically checking for garbage collection opportunities.
Multiply the above by 2,000 video candidates and run it against an archive file with 70,000 entries and you can easily end up with steps 6, 7, and 8 being executed almost 140,000,000 times if the matching strings are at the end of the archive. Python and other high-level languages make coding this stuff a lot easier than C, but it also makes it dead simple to slaughter your program’s performance since a lot of low-level details are hidden from the programmer.
I immediately recognized that the way to go was to read the archive file one time at program startup rather than reading it over and over for every single download candidate. I also recognized that this is the exact problem a binary search tree (BST) is designed to speed up. Thus, my plan was to do the same line-by-line read-and-strip as the current code, but then store each processed line in the BST, then instead of reading the file within in_download_archive(), I’d scan the BST for the string. The neat thing about a BST is that if it were perfectly balanced, 70,000 entries would only be 17 levels deep, meaning each string check would perform at most 17 string comparisons, a much better number than the 70,000-comparison worst-case of scanning a flat text file line-by-line.
So, I set out to make it happen, and my first commit in pursuit of the goal was dropped.


This actually worked nicely!…until I tried to use my huge archive instead of a tiny test archive file, and then I was hit with the dreaded “RuntimeError: maximum recursion depth exceeded while calling a Python object.” Okay, so the recursion is going way too deep, right? Let’s remove it…and thus, my second commit dropped (red is removed, green is added).

With the recursion swapped out for a loop, the error was gone…but a new problem surfaced, and unfortunately, it was a problem that comes with no helpful error messages. When fed my archive file, the program seemed to basically just…hang. Performance was so terrible that I thought the program had completely hung. I put some debug print statements in the code to see what was going on, and immediately noticed that every insert operation would make the decision to GO RIGHT when searching the tree for the correct place to add the next string. There was not one single LEFT decision in the entire flood of debug output. That’s when I finally realized the true horror that I had stepped into.
I had sorted my archive…which KILLED the performance.
Binary search trees are great for a lot of data, but there is a rare but very real worst-case scenario where the tree ends up becoming nothing more than a bloated linked list. This doesn’t happen with random or unordered data, but it often happens when the tree is populated in-order with data that is already sorted. Every line in my sorted file was “greater than” the line before it, so when fed my sorted archive, the tree became an overly complex linked list. The good news is that most people will not have a sorted archive file because of the randomness of the video strings, but the bad news is that I had sorted mine because it boosted overall archive checking performance. (Since new video downloads are appended to the archive, the most recent stuff is always at the end, meaning rejecting those newer downloads under the original archive code always required the worst-case amount of time.) It is entirely possible that someone else would sort their archive at some point, so I had accidentally set myself up in the worst-case scenario and I couldn’t just ignore it and assume no one else made the same mistake. I had to fix it.
I got 3/4 through changing over to a weighted BST before realizing that it would not improve the load times and would only help the checking behavior later. That code was scrapped without a commit. I had previously added weighted trees with rebalancing to jdupes, but removed it when all tests over time showed it didn’t improve performance.
How do you optimally feed sorted data into a BST? Ideally, you’d plop the data into a list, add the middle piece of data, then continue taking midpoints to the left and right alternately until you ran out of data to add (see this excellent tutorial for a much better explanation with pictures). Unfortunately, this requires a lot of work; you have to track what you have already added and the number of sections to track increases exponentially. It would probably take some time to do this. I decided to try something a little simpler: split the list into halves, then alternate between consuming each half from both ends until the pointers met. Thus, the third commit dropped.

This commit had two problems: the pointer checks resulted in failure to copy 2 list elements and the improvement in behavior was insufficient. It was faster, but we’re talking about an improvement that can be described as “it seemed to just hang before, but now it completes before I get mad and hit CTRL-C to abort.” Unacceptable, to be sure. I stepped away from the computer for a while and thought about the problem. The data ideally needs to be more random than sorted. Is there an easier way? Then it hit me.
I used ‘sort’ to randomize my archive contents. Problem: gone.
All I needed to do was randomize the list order, then add the randomized list the easy way (in-order). Could it really be that simple?! Yes, yes it can! And so it was that the fourth commit dropped (red is removed, green is added).
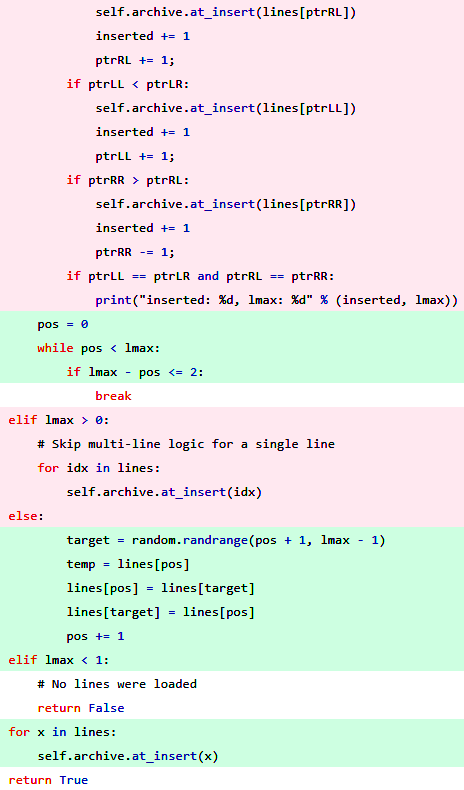
This worked wonderfully in testing…until I tried to use it to download multiple videos. I made a simple mistake in the code because it was getting late and I was excited to get things finished up. See if you can find the mistake before looking at my slightly embarrassing final commit below.
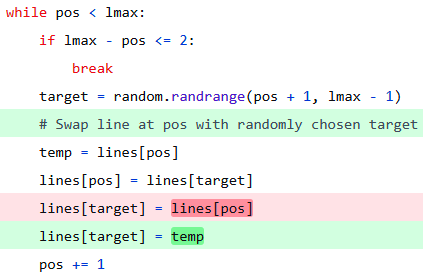
As I wrote this article, I realized that there was probably a cleaner way to randomize the list in Python. Sure enough, all of the code seen in that last commit can be replaced with just one thing: -random.shuffle(lines), and thus dropped my new final commit.
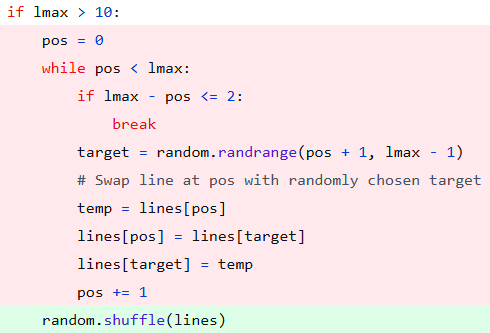
I think the code speaks for itself, but if you’d like to see the end result, make sure you watch the video at the top of this article.
Addendum
I posted this article to Reddit and got some helpful feedback from some lovely people. It’s obvious that I am not first and foremost a Python programmer and I didn’t even think about using Python sets to do the job. (Of course a person who favors C will show up to Python and implement low-level data structures unnecessarily!) It was suggested by multiple people that I replace the binary search tree with Python sets, so…I did, fairly immediately. Here’s what that looked like.
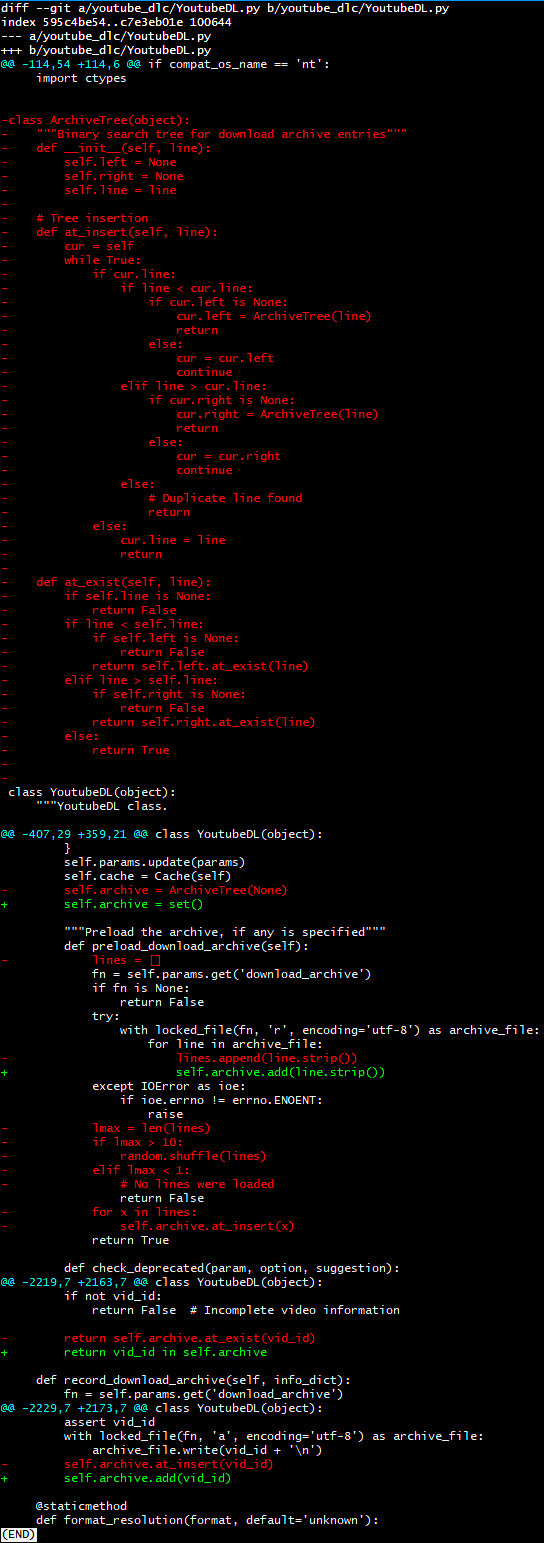
The Python set-based implementation is definitely easier to write and does seem to work well. If I did this again, I’d probably skip the BST with shuffle and just use sets. The performance is almost as good as the BST, but I ran a test using OBS Studio to capture output, then moving frame by frame to find the beginning and end of the archive checking process. The set version took 9 seconds; the BST version took 8 seconds. While the set version looks prettier, the fact that the BST has already been merged into upstream and is a bit faster means that the BST (despite probably offending some Python lovers) is here to stay. Actually, it turns out that I made a mistake: I tested the set version with ‘python’ but the BST version was compiled into an executable; after compiling the set version into an executable, it turns out that the set version takes about 6-7 seconds instead. Excuse me while I send yet another pull request!
If you have any feedback, feel free to leave a comment. The comment section is moderated, but fair.
Given how little RAM a list of URLs takes, relative to how much is available in a modern PC, it looks like their code was a premature optimization to limit the peak memory consumption.
Assuming they just wrapped the line-by-line iteration behaviour that
open()gives you, the dumb, simple, naive version of that algorithm is:with locked_file(fn, ‘r’, encoding=’utf-8′) as archive_file:
self.archive = [x.strip() for x in archive_file]
and that same
return vid_id in self.archiveline.Ugh. Your blog looks like WordPress but apparently doesn’t honour <pre> and <code>.
It’s WordPress. I don’t know why your comment didn’t format properly. Sorry about that.
I love youtube-dl and was glad to hear about youtube-dlc. But I was initially confused about claims that youtube-dlc is more actively updated since from what I can see today, youtube-dlc’s last update was in 2020 whereas youtube-dl’s last update is in 2021. But then your comment about youtube-dlc becoming yt-dlp directed me there where I see yt-dlp has indeed been updated recently.
I’ll definitely have to check out yt-dlp for future use.
I’m so happy to hear that I was helpful! Thanks for letting me know. It is rare that I receive such feedback, so it makes a big impact!
Hi Jody, I think this part is wrong:
“The neat thing about a BST is that if it were perfectly balanced, 70,000 entries would only be 374 levels deep, meaning each string check would perform at most 374 string comparisons, a much better number than the 70,000-comparison worst-case of scanning a flat text file line-by-line. (If you’d like to see how I found out that a balanced BST maximum depth is 374, try it out in this nifty triangle number calculator.)”
Depth of a BST will be approx: log(nodes)-1 which should be around 17. So it shouldn’t take more than 17 comparisons actually. Correct me if I am wrong.
Anyway thanks for writing this.
You are correct,
and I don’t know how or why I calculated that number at the time…actually, I inappropriately used a triangle number calculator, that’s what happened. Thanks for the correction; I’ll fix the article and stop looking silly to the global internet. 🙂