I got unsolicited bulk commercial email (otherwise known as spam) from “Flix Premiere” at an email alias I don’t actually use for anything these days. I unsubscribed without really reading it because it’s spam so as far as I’m concerned they can go get fucked with a rake, but as I waited for the unsubscribe page to load over my blazing fast connection, I glanced at the email once again to see what they were trying to do to gently separate me from my money without wining and dining me first.
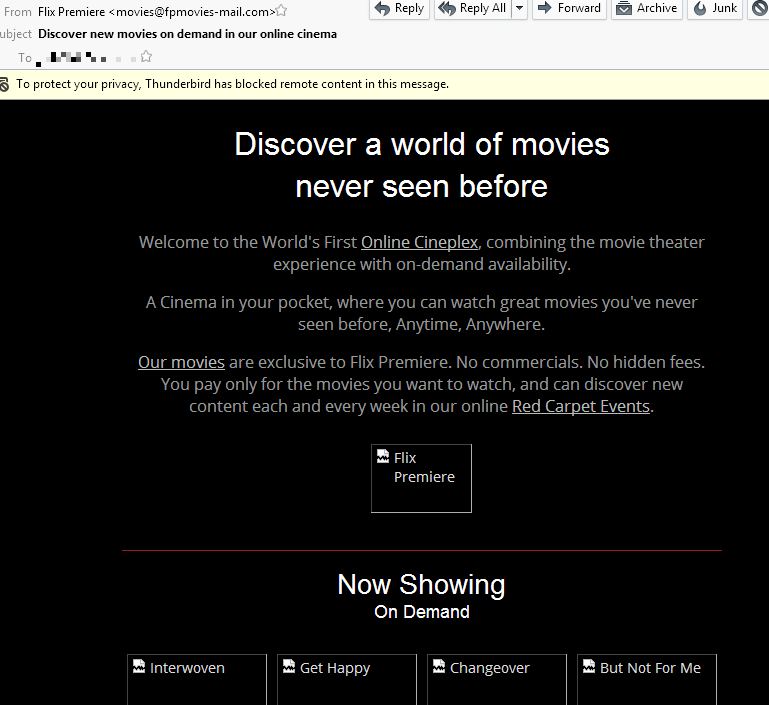
I have to admit that for sketchy spammy email this looks more convincing than usual…so I checked to see if they’re a real company with real products and no apparent malicious intent. They are indeed real, though that’s not going to save them.
Strike 1: Send me random opt-out spam like this and I’m already not interested.
Strike 2: I’ll let them tell you themselves.

Netflix has seen a nasty subscriber churn hit since they decided it’d be brilliant to jack up the cost for existing customers by yet another dollar per month. Netflix (as of today) now costs everyone $9.99 a month for a typical subscription. We’ll round up everything from here by one cent because that missing one cent is a single penny that represents a long-time pet peeve of mine with such deceptive pricing; yes, you weasely marketer assholes, $9.99 actually IS $10 in our minds, but thanks for insulting our intelligence right out of the gate!
So, in actual sane person dollars, Netflix is $10 a month. The header for Spamalot Films…er, *cough* I mean Flix Premiere…is (in sane person dollars) “just $5.” FLIX PREMIERE LETS ME WATCH ALL THE HIGH QUALITY INDIE FILMS THEY CAN CONTRACTUALLY CHOKE OUT EXCLUSIVE RIGHTS TO FOR $5 A MONTH?!
Flixy Downer replieth sternly: “Hold your horses, kid. It ain’t Netflix. It’s Flix Premiere, where we think we’re a cable television provider in 2001! It’s $5 to watch one film.”
Holy shit, Flix Premiere is expensive.
What the fuck were these people thinking? Netflix already has tons of indie films and they let you watch as much as you can cram into your face for $10 a month, be it one film or 100 films. Some brilliant idiot actually thought “we can ‘curate’ films no one has heard of from production companies no one has heard of and charge the same amount per two films that Netflix charges for a la carte viewing of both no-name and big-name films and television shows and make plenty of money doing so!”
No. No no no. The genie is out of the bottle, guys. A la carte streaming for single-digit monthly subscription prices is here to stay. You’re not going to convince the cord cutting revolution to go all the way back to five-dollar on-demand movies, especially when they’re not big-name films in the first place! Redbox rents physical Blu-Ray discs to people and still does it at 40% lower cost than your no-name streaming movies. What are you venture capital hemorrhaging execs smoking, and can you please keep it very far away from me?
On a positive note, it’s nice to see an interest in independent film. If it were $10 a month a la carte with a one-month free trial just like Netflix, I’d seriously consider joining up and sticking around if I liked it, despite the fact that they came to me under the seedy cloak of being cunty filthy spammers. At $5 a pop, you’re fucked in the head, out of your mind, and there’s no way in hell that I’ll even give them that one little sanity cent I’ve generously added to their prices this whole time.
Flix Premiere also runs around the Internet replying to comments to do damage control as any remotely functional company does, but they suck at it. I’m such a generous lord that I shall paste one of their comments here as a response so they don’t have to. I’ll even respond to that!
Flix Premiere squawked: “the great thing about Flix Premiere is that we’re building a carefully screened and curated selection of good films that might never have been seen anywhere else. All the content is also exclusive to Flix Premiere for at least a year! So if you are hoping to catch these films on Netflix you’ll have to wait somewhat longer.”
First off, I have no way of knowing if your “carefully screened and curated selection” or your definition of “good films” match up with my own subjective tastes, so that statement is meaningless. If you mean “we don’t offer up first year film school student films for $5 apiece” then congratulations, you’ve set the bar very near the ground! Anything beyond that is so subjective that you can’t make objective statements about your collection like that. Exclusive for at least a year? Sounds like you could be screwing over indie filmmakers to me; I want to know how much of that exorbitant $5 you’re really giving them. Yes, I know that my grubby a la carte demands may mean less money available in the pool to pass along, but that would require your members to rent more than two movies a month on average every single month and you’d have far more members on a subscription plan in the first place.
That last jab of yours is your only direct stab at getting customers from Netflix, so let’s address it as clearly as possible right now. I’ll have to wait to see it on Netflix?
Guess what?
I can wait.
Sorry, indie folks. You really shouldn’t have signed away the rights to your own films to a grossly overpriced platform if you wanted me to see it. Having made some short films myself, I can sympathize with your plight, but this is the path you chose. As for Flix Premiere, feel free to leave a comment or two. I am a tough god, but I am a fair god.
tl;dr: Flix Premiere is a nice idea that costs way too much and they sent me spam, so fuck them with a rake.